부동산데이터분석: 서울 매매가격 상승 전환시점 분석을 시작하며
서울의 아파트 매매가격 상승 전환 순서를 알고싶었습니다. 따라서 이번 분석을 해보기로 하였습니다. 물론 Python으로 분석할 예정입니다. 하지만 막무가내로 하기 앞서서 ChatGpt에 맡기면 이런 분석은 정말 쉬워집니다.
우선 본 분석에 앞서서 지난 포스팅을 읽지 않으셨다면 먼저 읽고 오시기 바랍니다.
파이썬(python) 사용을 위한 아나콘다(Anaconda) 설치 방법 정리(2024.07기준)
파이썬으로 한국부동산원 주간아파트가격동향 시계열 다루기(2024.07 기준)
ChatGpt로 아파트시계열 분석하기(2024.07월 기준)
부동산데이터분석을 위해 ChatGpt에 다음과 같은 프롬프트를 입력하다
ChatGpt에 파일을 업로드 한다.
아래 포스팅에서 다루었던 한국부동산원 주간아파트가격동향 시계열의 전처리 결과 csv파일을 ChatGpt에게 업로드 합니다.
파이썬으로 한국부동산원 주간아파트가격동향 시계열 다루기(2024.07 기준)
만약 위 포스팅을 과정을 생략하고 싶다면 아래 깃허브의 코드를 내려받기 하여서 그 중 r1_week.csv파일을 chatgpt에 업로드 해줍니다.
https://github.com/yangyunho/r1_week_series_preprocessing
프롬프트 전문
이어서 아래 프롬프트를 입력해서 chatgpt가 작업할 수 있도록 합니다.
1. area_code2=11 & gubun=1 행을 필터링한다.
2. sigun별로 m_dt값이 음에서 양으로 전환된 ymd 중 가장 늦는 날짜를 매매상승전환시점 이라고 한다.
3. ymd 날짜중 가장 늦은 날짜를 가장최근ymd시점 이라고 한다.
4. sigun별로 매매상승전환시점의 m_js와 가장최근ymd시점의 m_js 간의 변동률을 구한다. 이를 매매변동률 이라고 한다.
5. 그리고 sigun별로 매매상승전환시점과 가장최근ymd시점 간의 주 수를 계산한다. 이를 주수 라고 한다.
6. sigun명 중에서 강서구,양천구,구로구,영등포구,금천구,동작구,관악구,서초구,강남구,송파구,강동구 단어를 포함하고 있는 지역은 강남권역 그외 자치구를 강북권역 이라고 구분한다. 이 칼럼 이름을 권역구분 이라고 한다.
이렇게 해서 테이블을 만들어줘이후 각 프롬프트에 대해서 설명을 드려보도록 하겠습니다.
area_code2=11 & gubun=1 행을 필터링한다.
한국부동산원 주간아파트가격동향 시계열을 전처리한 파일 r1_week.csv에서 area_code2는 시도별 2자리 코드를 말합니다. 그리고 gubun에서 1은 시군구, 3은 시도를 뜻합니다. 13은 세종시를 말합니다. 따라서 서울 모집단 중 서울특별시 모집단을 제외한 나머지 25개 자치구를 선택함을 의미합니다.
sigun별로 m_dt값이 음에서 양으로 전환된 ymd 중 가장 늦는 날짜를 매매상승전환시점 이라고 한다.
sigun은 지역명 입니다. 서울 25개 자치구별로 매주 매매증감(m_dt) 값이 음에서 양으로 전환된 ymd 중 가장 늦는 날짜를 분석합니다. 매매증감(m_dt) 값이 음에서 양으로 전환됨은 매매지수(m_js) 값이 상승으로 전환됨을 의미하게 됩니다.
ymd 날짜중 가장 늦은 날짜를 가장최근ymd시점 이라고 한다.
본 통계중 가장 늦은 날짜는 가장 마지막 시점을 뜻합니다.
sigun별로 매매상승전환시점의 m_js와 가장최근ymd시점의 m_js 간의 변동률을 구한다. 이를 매매변동률 이라고 한다.
25개 자치구별 매매가격이 상승전환 된 뒤 가장 최근 까지 상승률을 구합니다. 이를 매매변동률 이라는 변수에 담습니다.
그리고 sigun별로 매매상승전환시점과 가장최근ymd시점 간의 주 수를 계산한다. 이를 주수 라고 한다.
sigun별로 몇 주 째 상승하고 있는지 분석하기 위해서 위 프롬프트를 작성하였습니다.
sigun명 중에서 강서구,양천구,구로구,영등포구,금천구,동작구,관악구,서초구,강남구,송파구,강동구 단어를 포함하고 있는 지역은 강남권역 그외 자치구를 강북권역 이라고 구분한다. 이 칼럼 이름을 권역구분 이라고 한다.
서울 25개 자치구를 강남권역과 강북권역으로 나눕니다.
명령한 프롬프트대로 ChatGpt가 파이썬 코드를 작성하다.
위 프롬프트로 챗gpt에게 명령했더니 다음과 같은 파이썬 코드를 작성해 주었네요. 여기서 참고할 점은 여러분이 똑같은 위 프롬프트를 입력하더라도 아래 코드와 다르게 작성해줄 수 있습니다. 다만 결과는 비슷하거나 동일하게 나타나게 될 것 입니다.
아래 코드에서 file_path와 output_path를 여러분 상황에 맞도록 변경해주면 될 것 입니다.
import pandas as pd
# 1. 데이터 로드 및 필터링
file_path = 'r1_week.csv'
data = pd.read_csv(file_path)
filtered_data = data[(data['area_code2'] == 11) & (data['gubun'] == 1)].copy()
# 2. 매매상승전환시점 찾기
filtered_data.loc[:, 'm_dt_lag'] = filtered_data.groupby('sigun')['m_dt'].shift(1)
turning_points = filtered_data[(filtered_data['m_dt'] > 0) & (filtered_data['m_dt_lag'] <= 0)]
latest_turning_points = turning_points.groupby('sigun')['ymd'].max().reset_index()
latest_turning_points.columns = ['sigun', '매매상승전환시점']
# 3. 가장최근ymd시점 찾기
most_recent_ymd = filtered_data.groupby('sigun')['ymd'].max().reset_index()
most_recent_ymd.columns = ['sigun', '가장최근ymd시점']
# 4. 매매변동률 계산
latest_turning_points = latest_turning_points.merge(
filtered_data[['sigun', 'ymd', 'm_js']],
left_on=['sigun', '매매상승전환시점'],
right_on=['sigun', 'ymd'],
how='left'
)
latest_turning_points.drop(columns=['ymd'], inplace=True)
latest_turning_points.rename(columns={'m_js': 'm_js_turning'}, inplace=True)
most_recent_ymd = most_recent_ymd.merge(
filtered_data[['sigun', 'ymd', 'm_js']],
left_on=['sigun', '가장최근ymd시점'],
right_on=['sigun', 'ymd'],
how='left'
)
most_recent_ymd.drop(columns=['ymd'], inplace=True)
most_recent_ymd.rename(columns={'m_js': 'm_js_recent'}, inplace=True)
result = latest_turning_points.merge(most_recent_ymd, on='sigun')
result['매매변동률'] = (result['m_js_recent'] - result['m_js_turning']) / result['m_js_turning'] * 100
# 5. 주수 계산
result['매매상승전환시점'] = pd.to_datetime(result['매매상승전환시점'])
result['가장최근ymd시점'] = pd.to_datetime(result['가장최근ymd시점'])
result['주수'] = (result['가장최근ymd시점'] - result['매매상승전환시점']).dt.days // 7
# 6. 권역구분
gangnam_districts = ['강서구', '양천구', '구로구', '영등포구', '금천구', '동작구', '관악구', '서초구', '강남구', '송파구', '강동구']
result['권역구분'] = result['sigun'].apply(lambda x: '강남권역' if any(district in x for district in gangnam_districts) else '강북권역')
# 정렬 및 포맷팅
result = result.sort_values(by='매매상승전환시점')
result['매매변동률_포맷'] = result['매매변동률'].round(2).astype(str)
formatted_sigun_names = ' → '.join(result.apply(lambda x: f"{x['sigun']} ({x['매매변동률_포맷']})", axis=1))
# 결과 CSV 파일로 저장
output_path = 'final_result.csv'
result.to_csv(output_path, index=False, encoding='utf-8-sig')
# 결과 출력
print(formatted_sigun_names)
# CSV 파일 다운로드 링크 제공
print(f"CSV 파일 저장 경로: {output_path}")
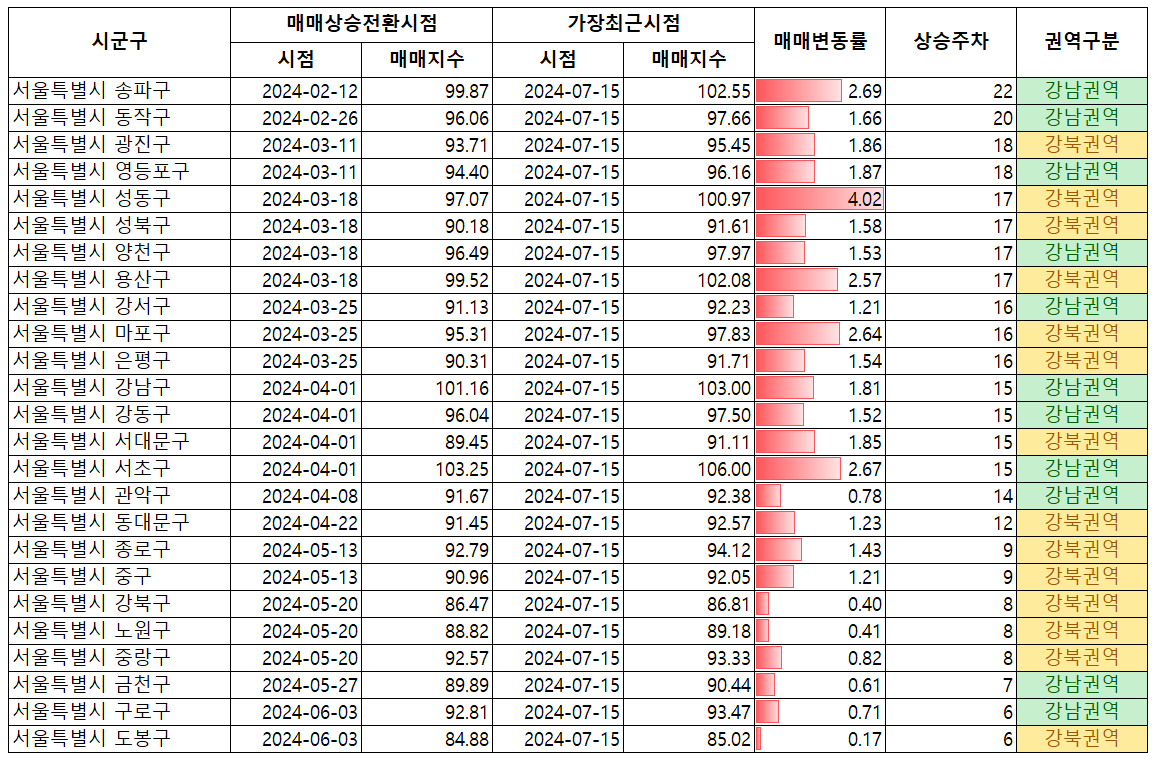
위 코드를 실행하고 얻은 csv파일을 excel파일로 변환해서 아래 처럼 가공해 보았습니다.

그리고 아래 현재 기준 서울 매매가격이 상승한 시점 순으로 지역을 나열할 수 있었습니다. 사실 이런 분석을 개인이 일일이 분석한다면 꽤 복잡한 분석이 될 것 입니다.
서울특별시 송파구 (2.69) → 서울특별시 동작구 (1.66) → 서울특별시 영등포구 (1.87) → 서울특별시 광진구 (1.86) → 서울특별시 용산구 (2.57) → 서울특별시 양천구 (1.53) → 서울특별시 성북구 (1.58) → 서울특별시 성동구 (4.02) → 서울특별시 마포구 (2.64) → 서울특별시 은평구 (1.54) → 서울특별시 강서구 (1.21) → 서울특별시 서초구 (2.67) → 서울특별시 서대문구 (1.85) → 서울특별시 강남구 (1.81) → 서울특별시 강동구 (1.52) → 서울특별시 관악구 (0.78) → 서울특별시 동대문구 (1.23) → 서울특별시 종로구 (1.43) → 서울특별시 중구 (1.21) → 서울특별시 노원구 (0.41) → 서울특별시 강북구 (0.4) → 서울특별시 중랑구 (0.82) → 서울특별시 금천구 (0.61) → 서울특별시 도봉구 (0.17) → 서울특별시 구로구 (0.71)
부동산데이터분석: 서울 매매가격 상승 전환시점 분석을 마치며
chatgpt가 생겨나면서 부동산데이터분석이 정말 쉬워졌습니다. 기존에는 Python코드를 일일이 학습하여서 구글링해서 원하는 결과가 나올 때 까지 디버깅하고 그랬습니다. 하지만 chatgpt가 생겨나면서 하고싶은 분석을 한글로 정리를 잘 할 수 있다면 이렇게 쉽게 원하는 결과를 얻을 수 있습니다.