파이썬으로 KB부동산 주간아파트가격동향 시계열 다루기 시작하며
매주 발행되는 KB부동산 주간아파트가격동향 시계열을 파이썬으로 다룰 줄 알면, 뉴스 또는 사람들 말에 현혹되지 않고 아파트시장 흐름을 보는 눈이 생겨납니다. 본 포스팅에서는 KB부동산 주간아파트가격동향 시계열 전처리하는 방법에 대해서 다룹니다.
본 포스팅을 읽고 따라하기 전 아래 포스팅을 먼저 읽고 오시기 바랍니다.
파이썬(python) 사용을 위한 아나콘다(Anaconda) 설치 방법 정리(2024.07기준)
한국부동산원 주간아파트가격동향 시계열 다루기를 원하시면 아래 포스팅을 참고하시기 바랍니다.
쥬피터노트북(Jupyter Notebook)으로 파이썬 파일 실행하는 법
깃허브 코드 내려받기
우선 아래 깃허브(github)에서 파일을 다운로드 받습니다.
깃허브 소스코드 다운로드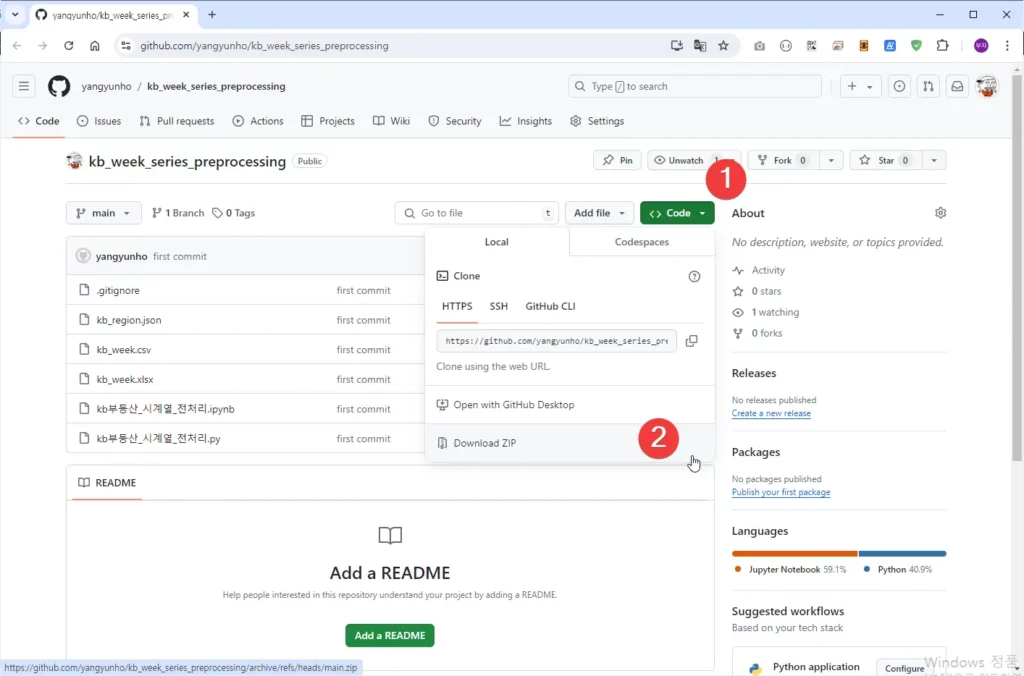
C:\Users\Administrator\Downloads\kb_week_series_preprocessing-main\kb_week_series_preprocessing-main
위 경로에 있는 파일들을 모두 각자 원하는 폴더로 이동시킵니다.
저의 경우 H:\파이썬코드모음\kb주간시계열다루기경로에 이동을 시켰습니다.
파이썬 전처리 코드
코드의 내용은 아래와 같습니다.(실시간 업데이트 반영된 코드가 아닙니다. 따라서 위 깃허브 소스코드 다운로드 버튼을 통하여 다운로드 받으셔서 사용하시기 바랍니다.)
# download_directory = "C:/Users/Administrator/Downloads"
# root_folder = "H:/파이썬코드모음/kb주간시계열다루기"
# 폴더경로 입력받기
download_directory = input("다운로드 디렉터리를 입력하세요: ")
root_folder = input("루트 폴더 경로를 입력하세요: ")
print("")
kb_region_2 = f"{root_folder}/kb_region.json"
print("-----------------------------------------------")
print("KB주간아파트가격시계열통계전처리작업시작")
###########################KB부동산주간시계열################################
from selenium import webdriver
import pandas as pd
import os
import shutil
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches", ["enable-logging"])
driver = webdriver.Chrome(service=Service(), options=options)
if download_directory == "default":
최초다운로드 = os.path.join(os.path.expanduser("~"), "Downloads") # 파일들이 들어있는 폴더
else:
최초다운로드 = f"{download_directory}/"
시계열파일이동할곳 = f"{root_folder}"
###############폴더만들기##############
def createFolder(directory):
try:
if not os.path.exists(directory):
os.makedirs(directory)
except OSError:
print("Error: Creating directory. " + directory)
createFolder(시계열파일이동할곳)
###############폴더만들기##############
driver.get("https://kbland.kr/webview.html#/main/statistics?blank=true")
time.sleep(2)
driver.find_element(By.XPATH, '//*[@id="__BVID__29___BV_tab_button__"]').click()
# 위코드는id가매번변경되어서아래코드로대체함
driver.find_element(By.XPATH, '//a[text()="주간아파트"]').click()
time.sleep(1)
driver.find_element(By.XPATH, '//*[@id="reference2"]/div[1]/button').click()
time.sleep(1)
file = 최초다운로드 + "/kb_week.xlsx"
if os.path.exists(file):
os.remove(file)
time.sleep(5)
# 가장최근파일가져오기
fileEx = r".xlsx"
file_name_and_time_lst = []
# 해당 경로에 있는 파일들의 생성시간을 함께 리스트로 넣어줌.
for f_name in os.listdir(f"{최초다운로드}"):
if f_name.endswith(fileEx):
written_time = os.path.getctime(f"{최초다운로드}/{f_name}")
file_name_and_time_lst.append((f_name, written_time))
# 생성시간 역순으로 정렬하고,
sorted_file_lst = sorted(
file_name_and_time_lst, key=lambda x: x[1], reverse=True
)
# 가장 앞에 이는 놈을 넣어준다.
# print(file_name_and_time_lst)
recent_file = sorted_file_lst[0]
recent_file_name = recent_file[0]
# print(recent_file)
print(recent_file_name)
time.sleep(5)
# 파일이름변경
os.rename(f"{최초다운로드}/{recent_file_name}", f"{최초다운로드}/kb_week.xlsx")
###############폴더내파일삭제##############
file = 시계열파일이동할곳 + "/kb_week.xlsx"
if os.path.exists(file):
os.remove(file)
###############폴더내파일삭제##############
# 방법 2 - 현재 작업경로와 상관없이 절대경로를 입력
# shutil.move('이동시킬 파일 경로', '파일을 이동시킬 폴더의 경로')
# 예시
shutil.move(f"{최초다운로드}/kb_week.xlsx", 시계열파일이동할곳)
############################KB부동산주간시계열################################
driver.close()
######################################################################
# 파일이름 나열하기
import os
import pandas as pd
from functools import reduce
import json
###################kb_week가져오기#################################
print("kb_week가져오기")
file_path = f"{root_folder}/kb_week.xlsx"
def kb_week(name):
df = pd.read_excel(file_path, sheet_name=name) # for구문으로 csv파일들을 읽어 들인다
# index가 0인 행만 삭제
# df = df.drop(index=0, axis=0)
# index가 0,1,2인 행 삭제
df = df.drop(index=[0, 1, 2], axis=0)
# 인덱스로 컬럼삭제시 끝에서 부터 삭제하여야 함
# if(name=="3.매매지수"):
# df = df.drop([df.columns[188]], axis=1)
# df = df.drop([df.columns[187]], axis=1)
# 제주도 컬럼 삭제
df = df.drop([df.columns[187]], axis=1)
# df
header = df.iloc[0]
# print(header)
header = []
for i in range(0, 189):
header.append(i)
# print(header)
df = df[df["Unnamed: 7"].notna()]
df.columns = header
value_vars = []
for i in range(0, 189):
value_vars.append(i)
df = df.melt(id_vars=0, value_vars=value_vars)
df = df.astype({"value": "float32"})
df.rename(
columns={0: "ymd", "variable": "index", "value": name.split(".")[1]},
inplace=True,
)
# df['val_type'] =name.split('.')[1]
return df
# kb_week("1.매매증감")
# kb_week("전세증감")
# kb_week("전세지수")
# kb_week("매매지수")
data_list = [
kb_week("1.매매증감"),
kb_week("2.전세증감"),
kb_week("3.매매지수"),
kb_week("4.전세지수"),
]
kb_week = reduce(
lambda x, y: pd.merge(x, y, on=["ymd", "index"], how="outer"), data_list
)
# kb_week = pd.concat([kb_week("1.매매증감"),kb_week("2.전세증감"),kb_week("3.매매지수"),kb_week("4.전세지수")])
kb_week
###################kb_week가져오기#################################
###################지역명_API가져오기#################################
print("지역명_API테이블 가져오기")
# DataFrame 생성 및 출력
region_api = pd.read_json(kb_region_2)
region_api
region_api.columns
columns = list(region_api.columns)
# print(columns)
# region_api.info()
region_api.astype("str")
region_api["area_code"] = region_api["area_code"].fillna(0)
# region_api =region_api.astype({'area_code':'float32'})
# region_api = region_api.astype({"area_code": "int64"})
region_api = region_api.astype({"area_code": "str"})
region_api["area_code2"] = region_api["area_code2"].fillna(0)
# region_api =region_api.astype({'area_code':'float32'})
# region_api = region_api.astype({"area_code2": "int64"})
region_api = region_api.astype({"area_code2": "str"})
region_api["area_code4"] = region_api["area_code4"].fillna(0)
# region_api =region_api.astype({'area_code':'float32'})
# region_api = region_api.astype({"area_code4": "int64"})
region_api = region_api.astype({"area_code4": "str"})
region_api["area_code5"] = region_api["area_code5"].fillna(0)
# region_api =region_api.astype({'area_code':'float32'})
# region_api = region_api.astype({"area_code5": "int64"})
region_api = region_api.astype({"area_code5": "str"})
# 176개지역 필터링하기
# region_api = region_api[(region_api['gubun']== 1)|(region_api['gubun']== 13)]
# region_api.info()
region_api
# ###################지역명_API가져오기#################################
###################두테이블조인하기##################################
# print("기존 시세테이블(mama4)과 region_api테이블 병합")
print("시계열&지역명 VLOOKUP작업1")
kb_week = pd.merge(
left=kb_week,
right=region_api,
how="inner",
left_on=["index"],
right_on=["index"],
sort=False,
)
kb_week = kb_week.astype({"gubun": "int64"})
kb_week
###################두테이블조인하기##################################
###################시군구매매증감전세증감순위매기기##################################
series = kb_week.copy()[
(kb_week.copy()["gubun"] == 3) | (kb_week.copy()["gubun"] == 13)
]
series
series["매매증감순위1"] = (
series.copy().groupby(["ymd"])["매매증감"].rank(method="min", ascending=False)
)
series["전세증감순위1"] = (
series.copy().groupby(["ymd"])["전세증감"].rank(method="min", ascending=False)
)
series = series[["ymd", "area_code2", "매매증감순위1", "전세증감순위1"]]
# 매매순위max=df2.groupby(['sigun_code','기준년월'])['매매평당가순위'].agg(['max'])
# 매매순위max.rename(columns={'max':'매매순위max'}, inplace=True)
###################시군구매매증감전세증감순위매기기##################################
###################두테이블조인하기##################################
# print("기존 시세테이블(mama4)과 region_api테이블 병합")
print("시계열&지역명 VLOOKUP작업2")
kb_week1 = pd.merge(
left=kb_week,
right=series,
how="left",
left_on=["ymd", "area_code2"],
right_on=["ymd", "area_code2"],
sort=False,
)
# kb_week = kb_week.astype({"gubun": "int64"})
kb_week1
###################두테이블조인하기##################################
###################시도매매증감전세증감순위매기기##################################
series1 = kb_week.copy()[
(kb_week.copy()["gubun"] == 1) | (kb_week.copy()["gubun"] == 13)
]
series1
series1["매매증감순위2"] = (
series1.copy().groupby(["ymd"])["매매증감"].rank(method="min", ascending=False)
)
series1["전세증감순위2"] = (
series1.copy().groupby(["ymd"])["전세증감"].rank(method="min", ascending=False)
)
series1 = series1[["ymd", "index", "매매증감순위2", "전세증감순위2"]]
# 매매순위max=df2.groupby(['sigun_code','기준년월'])['매매평당가순위'].agg(['max'])
# 매매순위max.rename(columns={'max':'매매순위max'}, inplace=True)
###################시도매매증감전세증감순위매기기##################################
###################두테이블조인하기##################################
# print("기존 시세테이블(mama4)과 region_api테이블 병합")
print("시계열&지역명 VLOOKUP작업3")
kb_week2 = pd.merge(
left=kb_week1,
right=series1,
how="left",
left_on=["ymd", "index"],
right_on=["ymd", "index"],
sort=False,
)
# kb_week = kb_week.astype({"gubun": "int64"})
kb_week2
kb_week2.rename(
columns={
"매매증감": "m_dt",
"전세증감": "j_dt",
"매매지수": "m_js",
"전세지수": "j_js",
"매매증감순위1": "m_dt_rank1",
"전세증감순위1": "j_dt_rank1",
"매매증감순위2": "m_dt_rank2",
"전세증감순위2": "j_dt_rank2",
},
inplace=True,
)
kb_week2 = kb_week2.sort_index(axis=1)
###################두테이블조인하기##################################
# ###################3테이블조인하기##################################
# data_list = [kb_week,series,series1]
# kb_week1=reduce(lambda x, y : pd.merge(x,y,on=['ymd','index'],how='outer'), data_list)
# # kb_week = pd.concat([kb_week("1.매매증감"),kb_week("2.전세증감"),kb_week("3.매매지수"),kb_week("4.전세지수")])
# kb_week1
# ###################3테이블조인하기##################################
kb_week2.to_csv(
f"{root_folder}/kb_week.csv", encoding="utf-8-sig", index=False
)
###################두테이블조인하기##################################
print("kb주간아파트가격시계열통계전처리작업종료")
print("-----------------------------------------------")쥬피터 노트북으로 실행하기
위 처럼 실행하면 아래 처럼 크롬브라우저(개인에 따라서 브라우저가 다를 수 있어요!!)로 쥬피터노트북 경로가 뜨게 될 것 입니다. 아래 이미지는 저의 경우 예시 입니다.
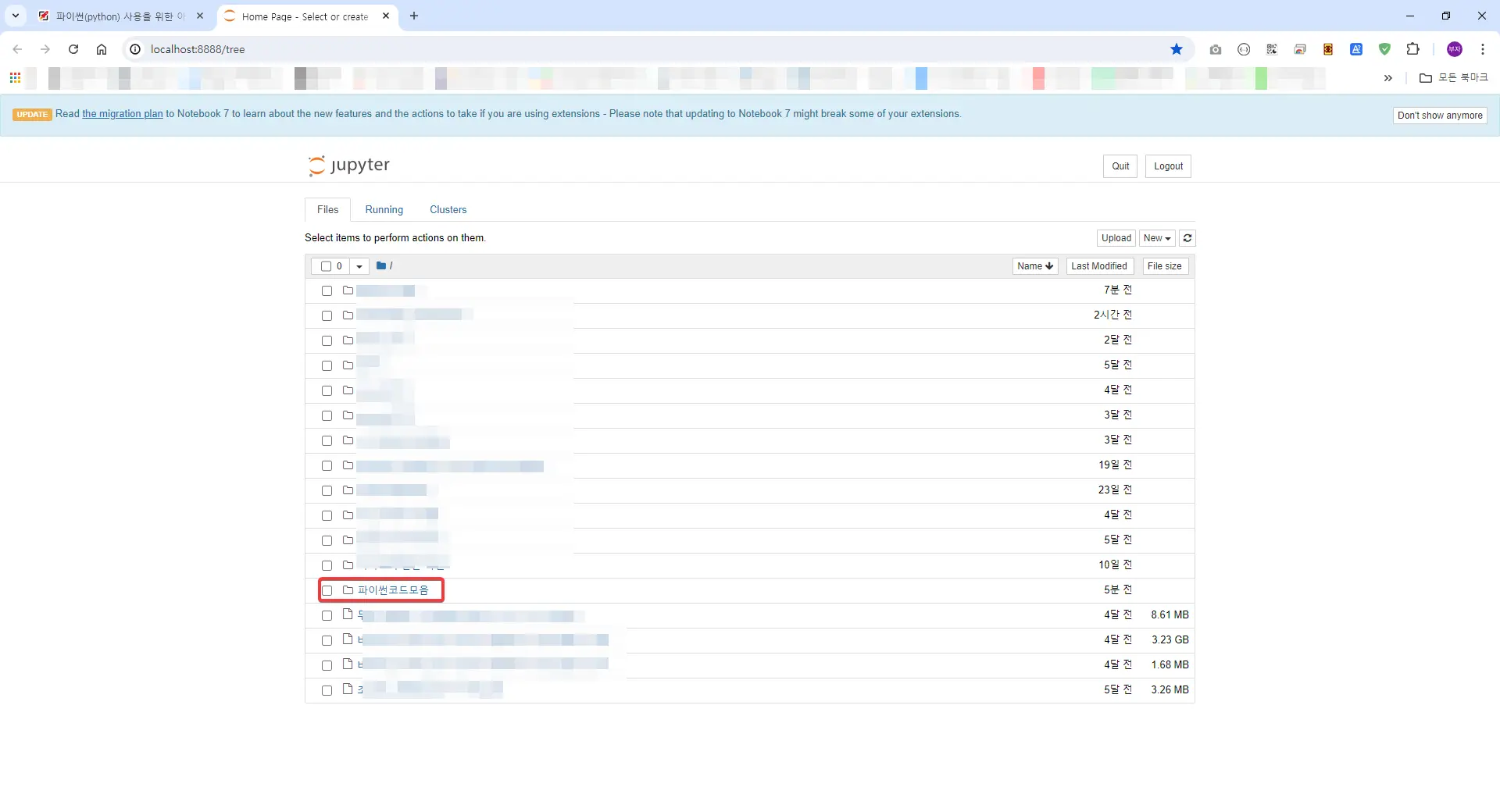
아래 해당 ipynb 파일을 열어서 들어갑니다.
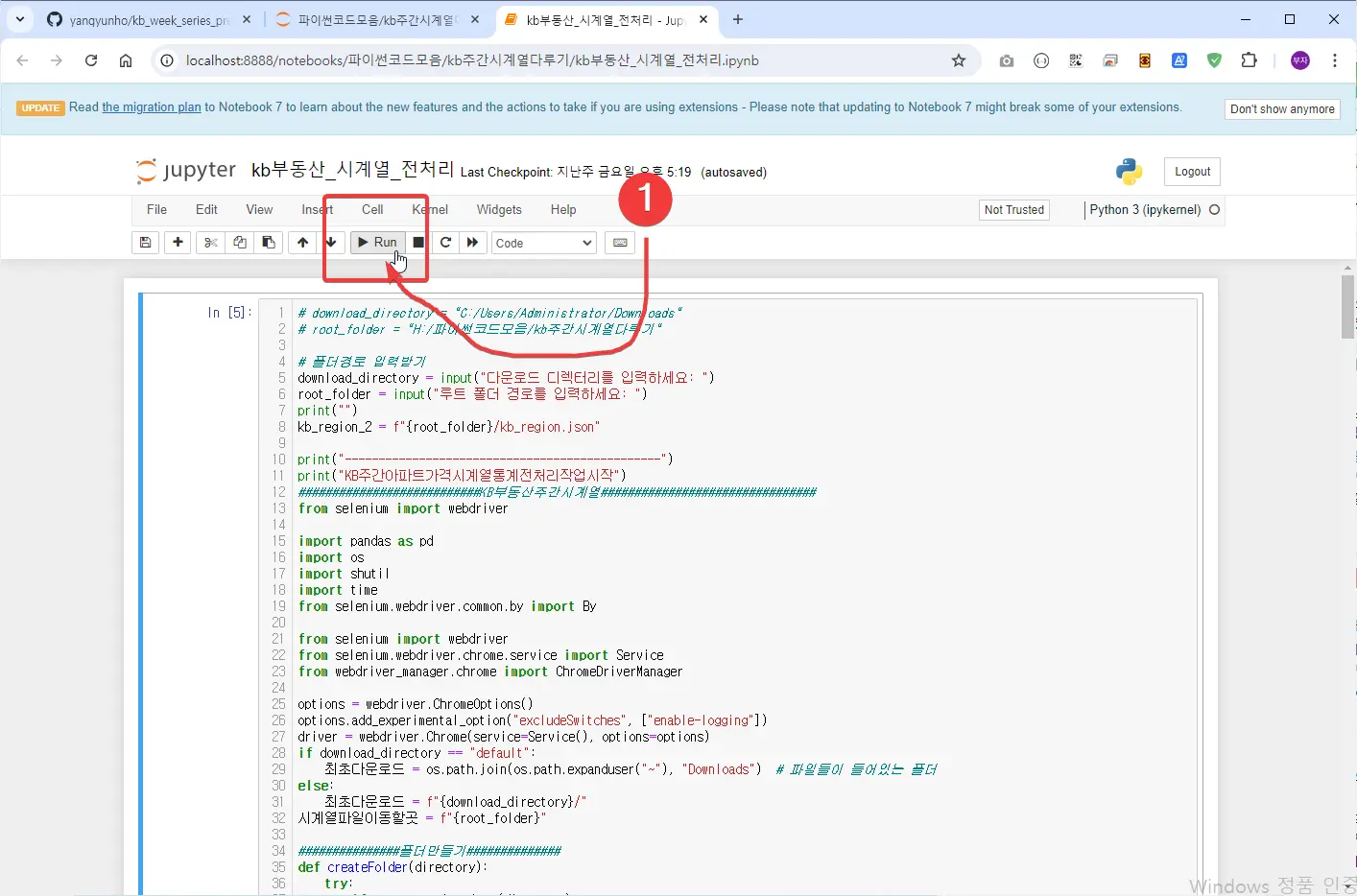
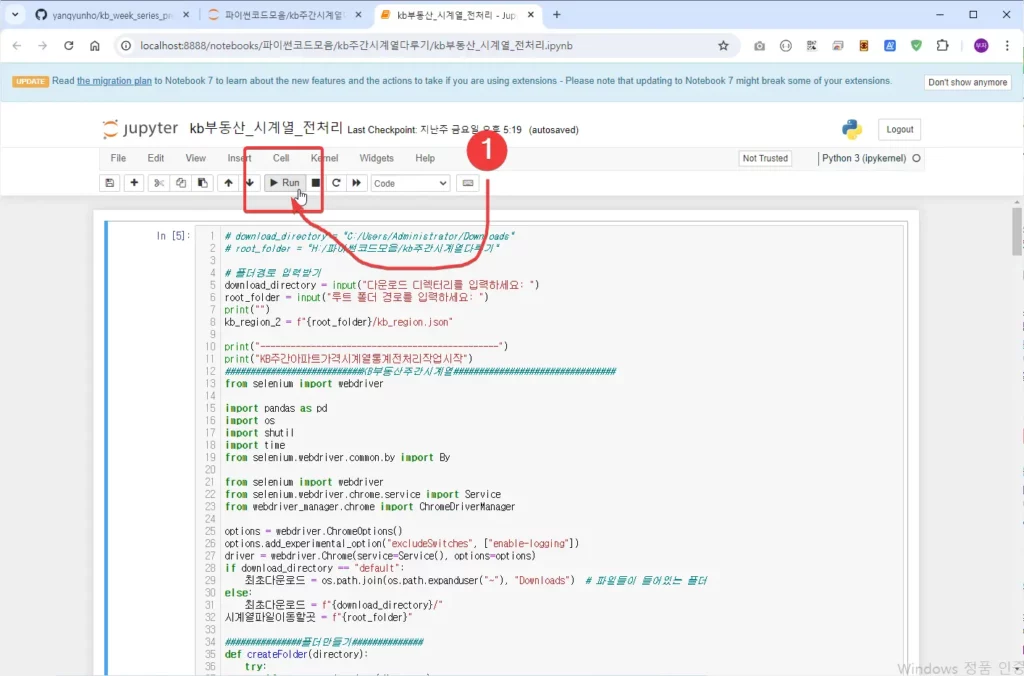
아래 처럼 Run을 클릭해서 실행합니다.
그러면 다운로드 디렉토리를 입력하라고 합니다. 통상 여러분의 Download 폴더가 될 것 입니다.
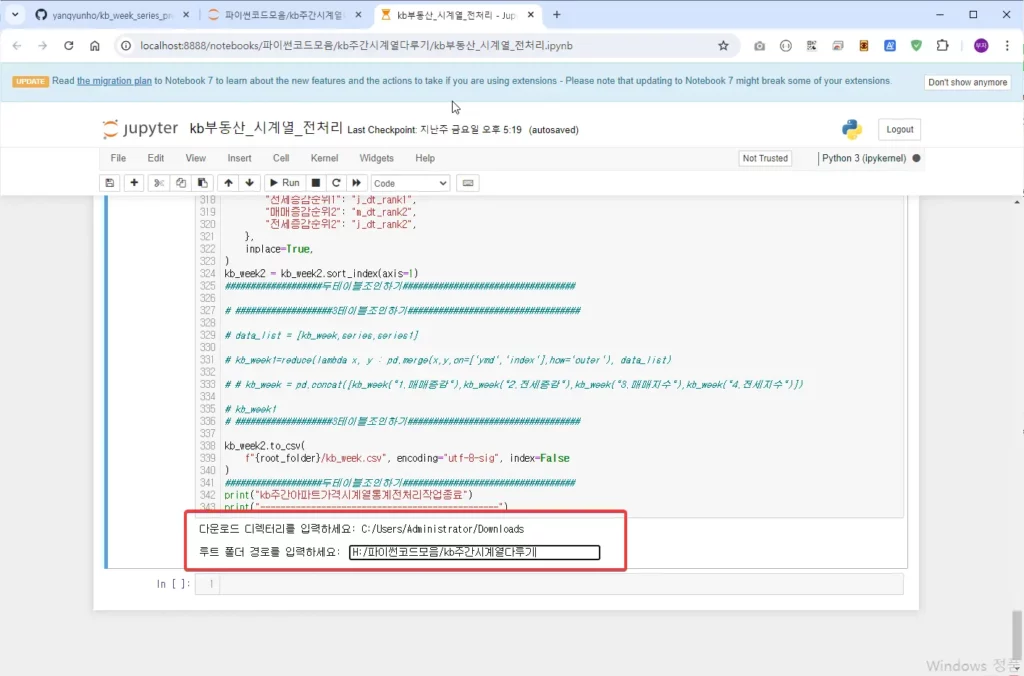
그 다음 루트폴더 경로를 입력하라고 나오면 저의 경우 아래 처럼 파일탐색기에서 파랗게 된 부분을 선택하시고 copy합니다.
그런다음 input창에 H:\파이썬코드모음\kb주간시계열다루기 넣어줍니다. 여기서 H:/파이썬코드모음/kb주간시계열다루기 로 변경합니다. ( \ —> / )
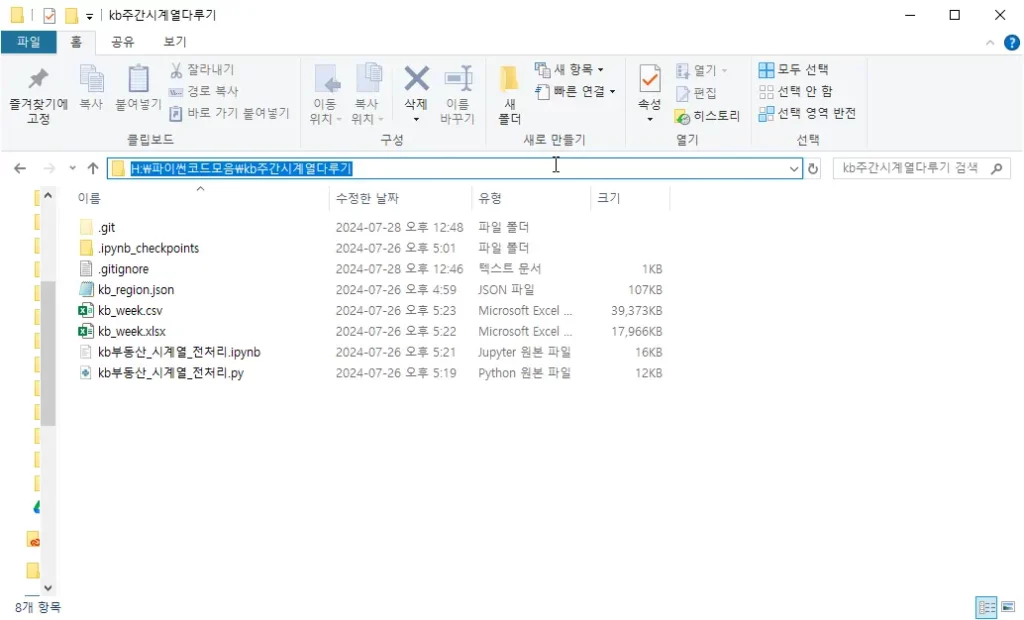
그런 다음 계속해서 코드가 실행이 되고, 얼마 지나지 않아서 실행이 완성되면 아래 폴더 처럼 KB부동산 주간아파트가격동향 시계열이 전처리 된 kb_week.csv 이 생성 될 것 입니다.
파이썬 KB부동산 주간아파트가격동향 시계열 다루기 마치며
이상 KB부동산 주간아파트가격동향 시계열을 다운로드 하여서 전처리하는 파이썬 코드를 쥬피터노트북으로 실행하는 방법에 대해서 살펴보았습니다.
이어서 이렇게 전처리 된 kb_week.csv파일을 챗GPT(ChatGpt) 로 불러들여서 보다 고급분석을 하는 방법론에 대해서 아래 포스팅을 참고하시기 바랍니다.
ChatGpt로 아파트시계열 분석하기(2024.07월 기준)
혹시 본 포스팅을 따라하시다가 에러나는 부분이 있다면 언제든지 댓글 주시면 함께 고민해보도록 하겠습니다.